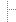|
Page last edited by Sune Lehmann Jørgensen (sljo) 20/02-2013
Formalia: Please read http://dtu.cnwiki.dk/02822/page/666/assignments-grading carefully
before proceeding. This page contains information about formatting
(including restrictions on size, etc), group sizes, and many other
aspects of handing in the assignment. If you fail to
follow these simple instructions, it will negatively impact your
grade!
Due date and time: The assignment is due
on Monday Feb 25th at 23:59.
Assignment:
Exercise 1. You already know how to program (it's a
course requirement), but how's your Python doing? Going over the
following exercises will help you feel more comfortable in a new
environment. Write a script that does
the following
- Create a list a that contains the
numbers from 1 to 990, incremented by one, using
the range function.
- Show that you understand slicing in Python by extracting a
list b with the numbers from 42 to 79
from the list created above. Here, it is sufficient to include
the commands in the assignment text.
- Using def, define a function that takes
as input a number x and outputs the number
multiplied by itself plus eight f(x)
= x(x+8). Apply this function to every
element of the list b using
a for loop. Include your function in the
assignment text.
- Learn about JSON by reading the wikipedia page. Why is json
superior to xml? (... or why not?)
Exercise 2. Use APIs to control the internet
- What is a Web API? Describe in your own words
(you may want to ask wikipedia or Google, if
you don't already know what an API is).
- What does it mean that a webservice is "RESTful"? Describe in
your own words.
- Write a Python script that generates the URL to draw a simple
pie chart with
Google Chart API. Make the pie with 5 slices, occupying
the following fractions: [4%, 7%, 14%, 25%, 50%]
- Use
Google's Static Map API to draw a straight line from your
house to DTU building 101.
Exercise 3. Play with Python's matplotlib (http://matplotlib.sourceforge.net/)
and real data.
- Go to the Guardian Data Store, http://www.guardian.co.uk/news/datablog+society/alcohol and
find the data on alcohol consumption across the globe: The per
capita recorded alcohol consumption (litres of pure alcohol) among
adults (older than 15 years). The data accompanies the article
"Boozers of the world" from 9 March 2009. Download the data to
your computer, clean it, and read it into Python. This part is
painful & more difficult than one might think. You'll have to
decide how to do this: will you get the data ready for Python via
excel, via google docs, import using a python tool? And how do you
handle missing values, etc.?
- First, find the top 5 drinking countries using Python (I
recommend sorting the list of countries in descending order, check
out http://wiki.python.org/moin/HowTo/Sorting).
- What number on the list is Denmark?
- Generate a simple line-plot of the countries'
consumption in descending order using the
matplotlib.pyplot (henceforth abbreviated as "plt")
command plot.
- Create a barchart of the same data, using the plt
command bar. What is the problem with this
visualization?
- Revise your barchart so as to emphasize the difference between
the countries that drink the most and the countries that drink the
least. To achieve this goal, construct a barchart of the top
15 and bottom 15 alcohol-consuming contries, with country
names on the x-axis. Something like this, but not
necessarily as fancy! Note: assignment continues below image.

Exercise 4. Download data from Flickr. [Note:
The way we did this for first set of exercises was sub-optimal, the
strategy below is much easier]. [New version -
edited Tue 16:00!]
- Extract the location data & tags for two or more sets of
pictures (at least 2x4000 pictures). For one set use 'beach, ocean'
as tag while for the other use 'nature, forest'. To get tags and
location, import the flickrapi module and use flickr.photos_search
with
arguments bbox, tags, format,
extras, and page to download all
tags.
- [Hint: You can
use flickr.photos_search(tags='nature, forest', bbox=[Coordinates for
Denmark], page=k, extras='tags', format='json') Note that
this strategy is very similar to the strategy in exercise 1;
basically extras='geo, tags'. Full
documentation for flickr.photos_search is
here]
- Remember to iterate over all the pages by using the
argument page=[number]
- Again, save all data!
Exercise 5. Plot the data on a map. Show the raw data
on a basemap and use
Hexbin (from the matplotlib package) to divide and plot
the geographical location of the pictures from Flickr into
bins.
- Plot the datapoints for the two sets of data on top of a
basemap, use different coloring for nature vs. ocean.
- Now combine the two datasets and use
Hexbin
(from the matplotlib package) to divide and plot the
geographical location of the pictures from Flickr into
bins.
- What are the advantages of binning rather than just plotting
the points? Can you think of a specific situation where binning
might help you see structure that you can't see by plotting simple
x,y coordinates? [Hint: find inspiration here.]
- With the data at hand, plot the hexbin over a basemap. Use
the extent option for alignment if you computer
has trouble getting the map and hexbin aligned (some of you may not
need to use extent). Transparency can be achieved through the the
"alpha" parameter. Hexbin has many other options - for example, you
can choose not to plot all of the bins that have no counts (check
the documentation to find what the option is called).
Exercise 6. Generate Word cloud for the photos
- Extract all tags from the newly obtained dataset, loop over the
files/dictionaries and add individial tags to a list ... or save to
a file.
- Use Wordle (or
similar, you can also use Python packages, etc) to create a Word
Cloud (disregard the used tags since they will appear in all the
tag lists).
- Which other tags are popular?
- Which other things can you learn about DK photos from the
word-cloud?
An note about optional exercises: It is not
necessary to complete the optional exercises!! It is possible to
get a perfect grade in this
class without completing the optional exercises
- these are added for the benefit of students who manage to complet
the mandatory exercises and need extra challenges. The optional
exercises are typically difficult.
Also note that it is not a waste of time to work on the optional
exercises. The way we credit work on optional exercises is that
correct answers on these exercises can make up for incorrect
answers on the mandatory exercises.
Exercise 7. [Optional] Generate region specific Word
Clouds.
- Generate one Word Cloud for Jutland (Jylland) and one for
Zealand (Sjælland).
- You can either do this by splitting the already downloaded data
into two geographic bounding boxes, or call the API again, this
time with bounding boxes for the two regions.
- As before extract all tags from the data and plot the Word
Clouds, do you observe any differences between the popularity of
tags?
Exercise 8. [Optional] Create a trace network for
the 10 users with most uploaded pictures.
- Go through your dataset and count how many pictures belong to
each user, the 'owner' field specifies a user.
- Extract geographical data for the 10 users with most pictures
(use the API). Remember to order the pictures accodring to their id
- which provides an indication of time (you may also acquire time
from the API).
- Using Basemaps and matplotlib, plot a network of the pictures
where the links are drawn between subsequent pictures.
- Color the traces of each user differently. What does the
network show? Can you distinguish any patterns between the various
users?
- Inspiration:

This page will be permanently deleted and cannot be recovered. Are you sure?
|